机器学习-pt-2-深度学习
台大李宏毅老师的机器学习课程学习笔记
视频资源:BV1Wv411h7kN
framework of ML
- training data
- training
- function
- loss
- opyimization
- testing
model bias
- model is too simple
- make model more flexible:
- more features
- deep learning
optimization issue
- gain the insights from cpmparison
- start from shallower networks, if deeper networks do not obtain smaller loss, then optimization issue
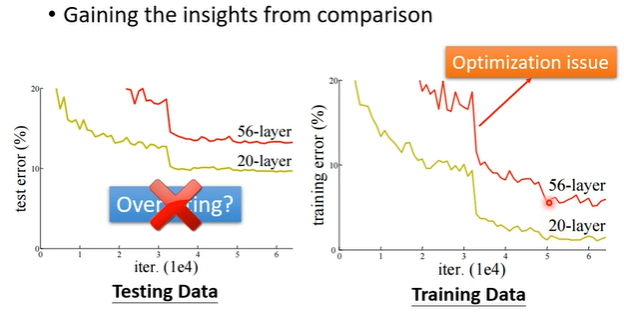
overfitting
- small loss on training data, large loss on testing data
- more training data 即可
- data augmentation (创造资料,eg将图片左右翻转等)
- 不能随意创造,例如将图片上行下反转
- constrained model
- eg. 直接限制为二次曲线
- less parameter, sharing parameter (CNN)
- less feature
- early stopping
- dropout
- regularization 正则化
- do not constrain too much -> otherwise model bias
mismatch
- training and testing data have different distributions
optimization
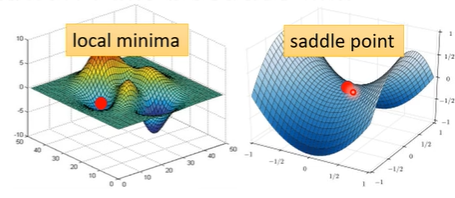
critical point
- local minima & saddle point
根据hessian来判断critical point的类型
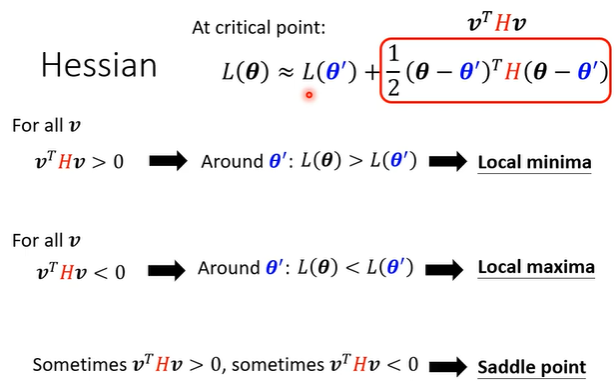
或观察H,H正定则local minima,负定则local maxima
对于saddle point,H对应的特征值必有正有负,根据负特征值求出对应特征向量,将此作为梯度进行下降即可(seldom used)

可以通过转化到更高维空间的方式将local minima转化为saddle point
batch
对于所有的数据分为不同的batch,遍历所有batch称为一个epoch,用一个batch内的数据更新一次参数。
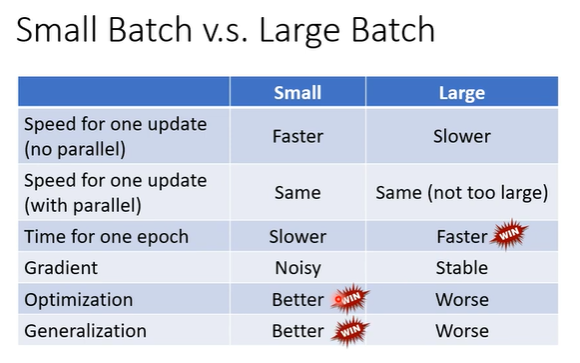
batch的size大小不同,训练的效果也不同。
结合了并行运算(parallel computing)的大尺寸batch梯度下降的训练结果更好,运行一个epoch的时间也相对更少。
- 并行计算下,每个batch1笔数据和1000笔数据的运算时间基本相同。
小尺寸的batch在优化过程中不易陷入saddle point,从而获得更好的training和testing的结果。
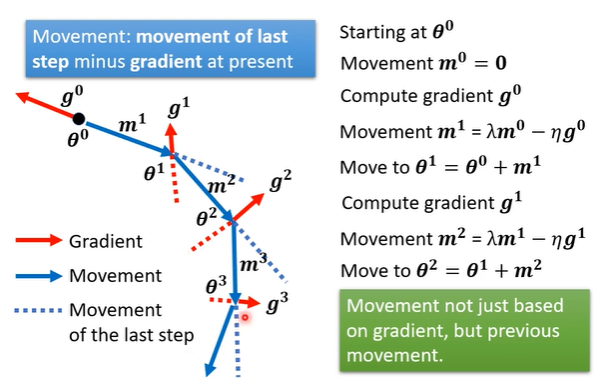
momentum
利用物理世界中的“惯性”来冲出saddle point。
每次下降的方向由计算出的梯度和上一次下降的方向共同决定。
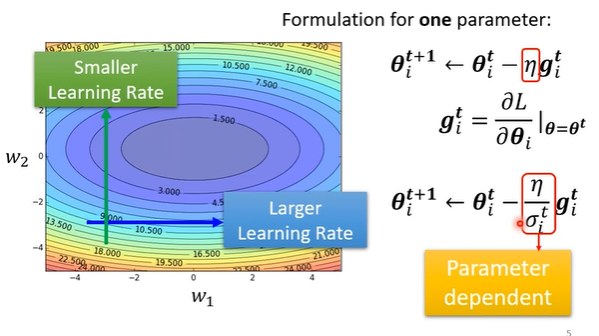
客制化的梯度下降(adaptive learning rate)
解决不同方向上梯度变化情况不同,导致一个单一的学习率无法适应所有方向的问题
对每一个参数的学习率进行修饰
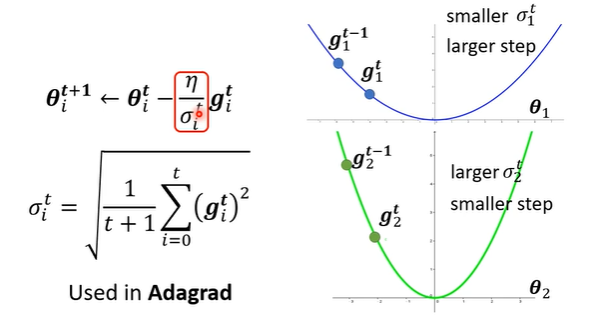
σ使用之前所有梯度的均方根确定
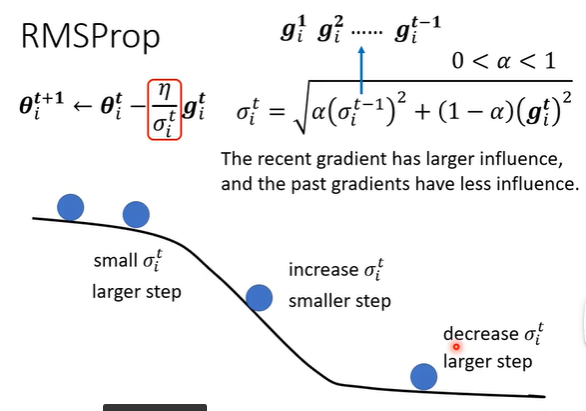
确定σ的更好方法:RMSProp
learning rate scheduling
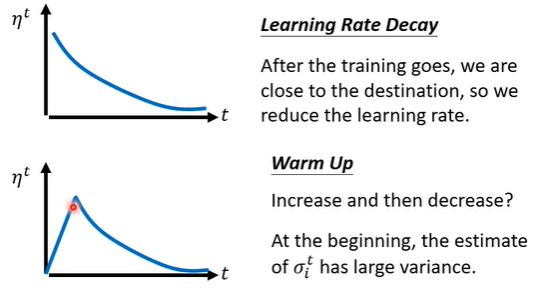
summary
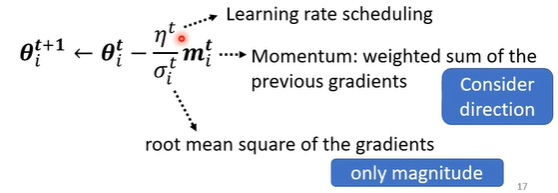
momentum和客制化调整的是学习率的不同角度:
- momentum不仅考虑了之前所有学习率变化的大小,同时考虑了方向(矢量角度)
- 客制化调整仅仅调整了学习率变化的大小(标量角度)
Eg. 数码宝贝分类器
机器学习-pt-2-深度学习
http://eskildmk.github.io/2022/10/25/机器学习-pt-2-深度学习/